 Stadt und Gemeinschaft. Soziale Netzwerke im mittelalterlichen Wien
Stadt und Gemeinschaft. Soziale Netzwerke im mittelalterlichen Wien— coming soon —
1) Die formale Datenerschließung der semistrukturierten Graphen-Datenbank basiert auf den über die Urkundenplattform monasterium.net verfügbaren Urkundenregesten der Quellen zur Geschichte der Stadt Wien (QGStW) und den mittels automatischer Texterkennung in XML-Format umgewandelten Einträgen der Wiener Stadtbücher. Bislang wurde die Datenerfassung dieses Quellenbestandes vom Beginn der Überlieferung (13. Jhdt.) bis 1404 abgeschlossen, das sind knapp 1.700 Dokumente mit über 11.000 Nennungen von Personen, die sich ihrerseits (aufgrund von Mehrfachnennungen) in über 5.000 individuelle Personen, davon knapp 30% Frauen zusammenfassen lassen.
Die Modellierung der Datenbank orientiert sich am Muster der factoid prosopography. Die Aufbereitung der Daten, die Anlage der Register und die Auszeichnung (tagging) der Textsegmente erfolgen mit Hilfe des XML-Editors Oxygen und basieren auf den Richtlinien der TEI. Zur Auswertung von in diesem Erfassungsschema ausgezeichneten (getaggten) Quellenbeständen wurden python-Programmierungen für jupyter-notebook erstellt.

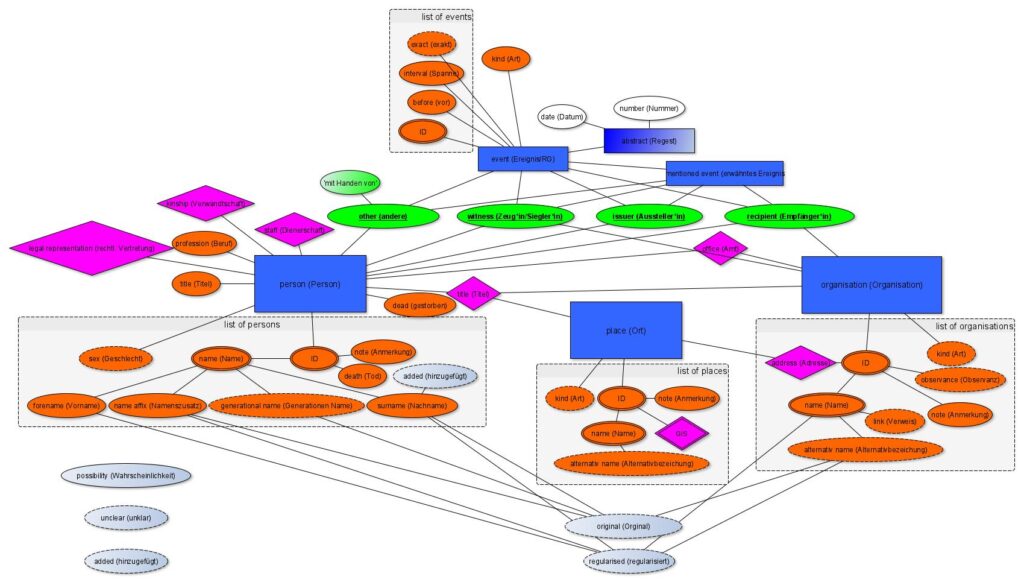
2) Zentrale Analyseeinheiten der Datenbank (entities) sind Personen (persons), Organisationen (organisations) und Ereignisse(events), deren Kern das Datenerfassungsmodell für die Analyseeinheiten (entity-relationship-model) bildet. Dieses basiert auf der Auszeichnung von Textpassagen (in den im XML-Format vorliegenden Quellentexten) und Registern der Analyseeinheiten (indices). Die Verknüpfung beider Bereiche geschieht mit Hilfe von Graphen (IDs und Verweise auf IDs). Das Modell strukturiert für die Analyseeinheiten – neben ihrer Auszeichnung im jeweiligen Text und ihrem Eintrag im Register – auch die Möglichkeit der inhaltlichen Erfassung in Bezug auf ihr Auftauchen in Ereignissen und ihren Funktionen in Rechtsgeschäften sowie die Ausstattung mit Attributen und relationalen Verbindungen.
Dieses Modell wurde im Zuge der Erfassung eines neuen Bestandes (Wr. Stadtbücher) mit teilweise erweiterten inhaltlichen und strukturellen Logiken deutlich verfeinert, sodass künftig auch eine Anwendung auf weitere Quellenbestände möglich sein wird. Die neuen Programmierungen betreffen besonders die weitere Differenzierung der Auszeichnungsebenen, die Normierung der roleNames und die Registerentwicklung.
3) Perspektiven
Mit dem neuen Quellenkorpus (Wiener Stadtbücher) wurde eine Differenzierung der Auszeichnungsebenen für künftige vergleichende Auswertungen der Quellenkorpora (Urkunden, Stadtbücher) sowie die Programmierung mehrerer neuer Skripten notwendig, um 1) eine gleichförmige Annotation der Quellentexte, 2) eine simultane Synchronisierung der erfassten Daten, 3) deren Weiterverarbeitung in verschiedenen Dateiformaten sicherzustellen.
Gleichförmige Eingabe durch XSD/DTD-Dokument: Kern der technischen Weiterentwicklung der Datenbank war die Programmierung eines sogenannten XSD-Dokuments, das in der individuellen digitalen Arbeitsumgebung von mehreren Bearbeiter*innen das kohärente Erfassen der Daten durch die vorstrukturierte Eingabe erfolgt und so die Qualitätssicherung simultanen Arbeitens sicherstellt. Zudem wurden zur Fehleranalysen Skripten programmiert, die es ermöglichen, Listen von häufig auftretenden Fehlern auszuwerfen, die zur zügigen Endkorrektur von Quellenbeständen beitragen.
Ein weiterer Fokus lag auf der Ausweitung der Analysemöglichkeiten der erfassten Daten sowie deren Export in Dateiformate, die in Form von CSV-Tabellen für Benützer*innen lesbar bzw. in verschiedene netzwerkanalytische Softwareanwendungen übertragbar sind. Der Zugang zum digital annotierten Quellenmaterial erfuhr insofern eine Differenzierung in der Tiefenerschließung, als nun Tabellen generiert werden, die z.B. eine Organisation sowohl als Ganzes (z.B. Pfarre St. Stephan) als auch in ihren Subeinheiten (Kapellen, Altäre, Messen der Pfarre von Stephan) kenntlich machen. Weitere Auswertungsmöglichkeiten bieten das Filtern des Materials nach dem catchwords, d.h. nach den originalsprachlichen dispositiven Verben, die eine Rechtshandlung beschreiben, womit sich neue Möglichkeit der Kategorisierung mittelalterlichen Rechtsgeschäftstypen eröffnen.
Zum weiteren Filtern wurden sogenannte Merge-Liste erstellt, welche einen schnellen Überblick zu den erfassten Entitäten ermöglichen. So lässt sich zum Beispiel die Häufigkeit, die Quelle und die Jahre des Auftretens von Personen leicht abrufen.
Die unterschiedlichen Attribute, mit denen Personen je nach Nennung erfasst werden können, werden automatisiert in die Listen überführt, was auf die Weiterentwicklung der sogenannten roleNorm-Konkordanz-Liste zurückgeht. In dieser sind mittlerweile 1672 Schreibweisen von Berufen, Ämtern, Bezeichnungen von Verwandtschaftsverhältnissen und Beziehungen zu Dienerinnen und Dienern gesammelt, welche laufend automatisiert in eine normierte Schreibweise überführt werden.
Die Überprüfung möglicher Register-Konkordanzen der zu annotierenden Personen in den beiden unterschiedlichen Quellenbeständen (bisher: Quellen der Geschichte der Stadt Wien; neu: Stadtbücher) gestaltete sich aufgrund des Fehlens von Registern für die Wiener Stadtbücher deutlich zeitintensiver als ursprünglich veranschlagt. Dieser methodische Vorgang der akkordierten Registererstellung, v.a. der eindeutigen Identifizierung der im Quellenmaterial erfassten Personen, ist allerdings eine unerlässliche Voraussetzung, um robuste Daten für jede Art der Auswertung und eine nachvollziehbare Identifizierung von Personen zu gewährleisten.
Durch diesen Arbeitsschritt entsteht ein vernetztes Register zu den Personen und Organisationen, das die online abrufbaren realienkundlichen und rechtshistorischen Sachregister der Wiener Stadtbücher (https://www.imareal.sbg.ac.at/die-wiener-stadtbuecher) optimal ergänzt.
Der Fortgang der Datenerfassung verlangsamte sich im Vergleich zum bisherigen Quellenkorpus insofern, als in den Wiener Stadtbüchern die absolute Anzahl der zu identifizierenden Personen – im Vergleich zu den bisher bearbeiteten Regesten der Quellen der Geschichte der Stadt Wien – um fast das Doppelte (von 3 auf 5,6 Personen/Urkunde) ansteigt. Bislang war nur aus qualitativen Studien bekannt, dass in den Wiener Stadtbüchern durch ihre Funktion in der städtischen Verwaltung vermehrt Personen städtischer Unterschichten auftreten, nicht aber das Ausmaß dieser Steigerung.
Besonders der erhebliche Anstieg an Nennungen von Personen, die nur einmal genannt werden und aufgrund des Kontextes sehr wenige Anhaltspunkte zu einer raschen Identifizierung bieten, war deutlich stärker als erwartet. Diese Zunahme führt im Zusammenhang mit dem Auftreten von sogenannten Verwandtschaftsweisungen (als verschriftlichte Rechtshandlung ca. 20% Prozent des ersten Bandes der Wiener Stadtbücher), die bislang kaum erforscht sind, zu einem sehr starken Anstieg an entsprechenden Nennungen von verwandtschaftlichen Verbindungen, die wiederum nach dem Schema der Datenerfassung für jede Person explizit annotiert werden.